
Problem Statement
Many batch processing systems available today are commercial systems that use proprietary technology (hardware / software) for performing the tasks. Those with Mainframe systems were quite prevalent. Such systems do have complex monitoring and control software. But these are relatively inflexible, tightly coupled with other, associated software and/or hardware, thus limiting scalability to the extent the platform supports. Added to this is the cost overhead of upgrading the system when more computational power is needed. With the advent of Cloud Computing technologies, these problems have been addressed to a growing extent. However, the cost quite often becomes a deterrent for many of the medium-scale enterprise systems.
Major challenges of such systems:
- Many are proprietary systems.
- Applications are not portable across multiple platforms.
- Interfacing with heterogeneous systems is always cumbersome work.
- Difficult to upgrade or introduce new and / or better technologies.
- Technology upgrades come with associated costs.
However, it is possible, with inexpensive and open-source technologies available today, to build a highly scalable and distributed system that is reliable and fault-tolerant. With the advent of virtualization technologies, the build and deployment of such systems have become quite flexible.
What Is Distributed Computing?
A Distributed Computing environment is a collection of heterogenous systems (of varying capabilities), located over a network. They coordinate computing operations by exchanging messages between one another. There are several autonomous components in a distributed system, such as dispatchers, processors, schedulers, monitors, etc. Each is designed to handle failure and recovery. Complex processing computing problems are broken down into smaller independent problems and dispatched to available processors. Additionally, a scheduler component can assign priorities to these tasks, and a monitor can monitor the progress of the tasks being processed. Each of these components is designed to handle failover in a seamless manner. The diagram below shows a typical scenario of the components distributed over several networks.
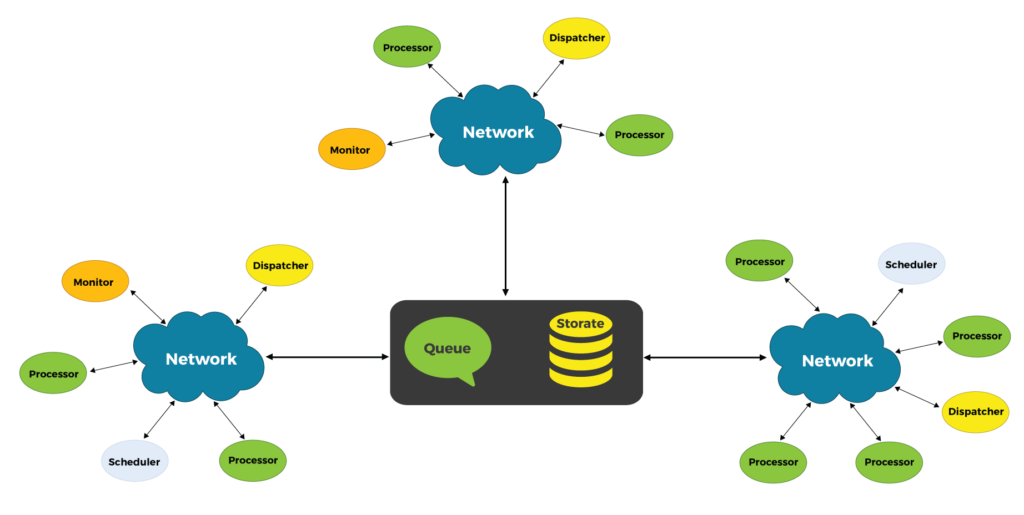
Proposed Solution
In this article, I will discuss an approach and feasible implementations of a priority-based task processing system with monitoring and load distribution capability. It is assumed that there is more than one processor available, but not necessarily online, in the system. This means that the system can process a task but may not be available at present. When available in future, it can pick up the task and complete the processing. The system can have reporting capability through its own persistence, possibly through a local or remote database. So the status of tasks is maintained in the persistence medium, a database. Since the information about the tasks is available centrally, load distribution can easily be supported. A typical component layout with communication flow is depicted in the diagram below.
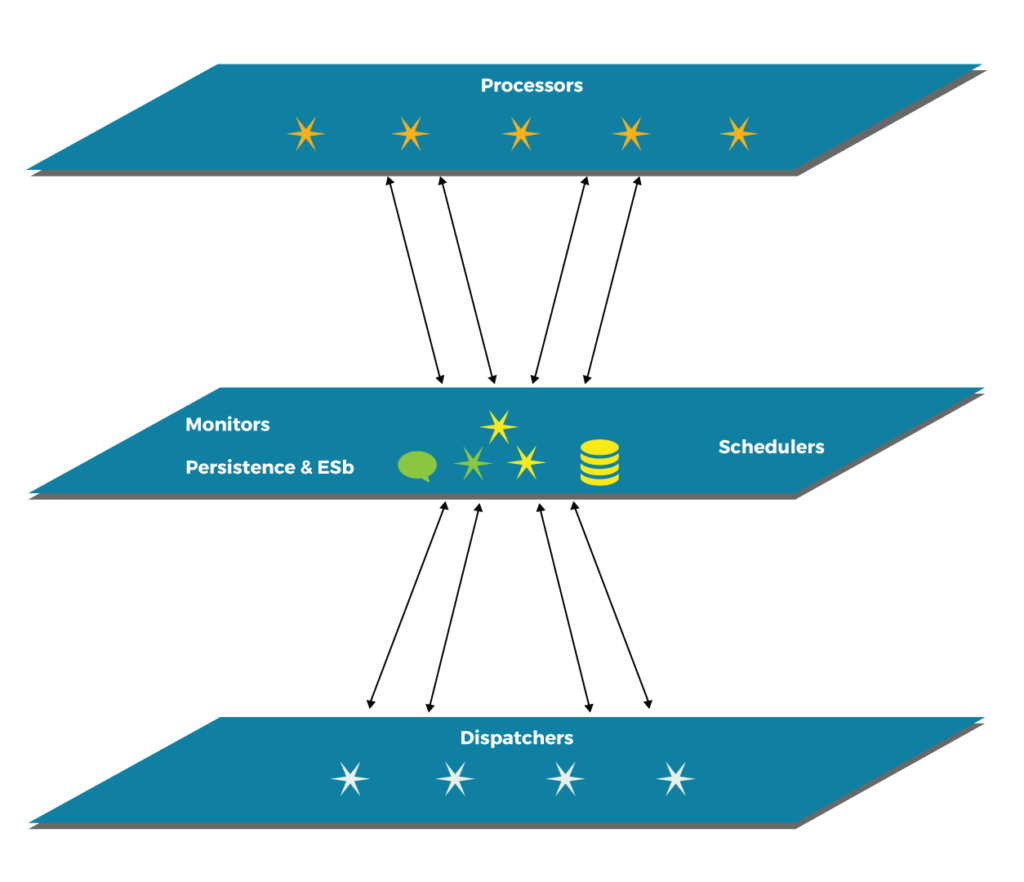
The responsibilities of a dispatcher are to prepare a task for processing and assign a priority as needed. It then submits the task to the scheduler. The schedulers will receive the task, assess the computing needs, identify the processor best suitable for processing, and then submit to the target processor. The processors will have their own priority pools. Based on the priority, the processor will assign the task for processing to its internal threads.
It is important that the scheduler identify the load on each of the processors and balance it by finding the most suitable processor for a given task. Several algorithms are used for this purpose. These include Sender-initiated and Receiver-initiated load balancing. In the case of a Sender-initiated algorithm, the scheduler analyses the load on the system, identifies the best possible processor, and distributes the task accordingly. In the case of a Receiver-initiated algorithm, the processor, upon receipt of a task, analyses its current load, analyses the load on others, and then re-distributes the task if needed. There are also hybrid systems that implement both algorithms for better performance.
The technologies used to implement such a system are:
- Java—Programming Language
- Active MQ—Message Queue
- MySQL—Database
The following are the salient features of the proposed system:
- Heterogeneous nodes
- Enterprise Service Bus (ESB)
- A central database
- One or more monitors
- One or more processors
- One or more dispatchers
- Tasks can be submitted from any node in the network.
- Processors as well as Tasks can be monitored periodically.
- One or more Monitors can perform the task of monitoring messages and update the database.
Case Study: A GDSN-Compliant Data Sync Engine
A GDSN-compliant Data Sync Engine was designed for a large Product Data Management company in Europe, as a distributed system. The complex task of processing Product information is broken down into smaller, computable pieces (i.e., parsing, transformation, analysis, validation, synchronization). This achieves the scalability needed to process and synchronize millions of messages per day. The components were divided, designed as Communication and Load Balancer, Analyzer, Translator, Importer, Exporter, and Dispatcher. Each one was independent and could be scaled up or down as needed, through suitable configuration. The components could be deployed in one large system or deployed over several nodes in a network.
Conclusion The framework presented here can easily be implemented in a heterogeneous network of systems of varied capacities. The processors need not have identical capabilities. Depending on the processing capacity of the systems, the processors can be configured to have starting from one to any number of Threads with the required pool size and associated priority. The health and load of the processors in the network are available to any component in the network. The dispatchers running anywhere on the network can utilize this information for efficient routing.

About the author – A.P. Mohanty
A.P. Mohanty has a B.Tech. in Instrumentation and M.Tech. in computer science. He also holds an MBA degree in Technology Management. He has over 20 years of experience in architecture and design of large Centralized, Enterprise Systems like Core Banking, Depository Systems, Currency Management, Data Synchronization, etc. He has published several technical papers in international journals and presented in international conferences.